Azure Data Fundamentals | DP-900 | what you need to know

I just completed the certification- Microsoft Certified: Azure Data Fundamentals
Note: If you are looking for tutorials, then the official videos at Microsoft DP-900 site are more than enough. You don't need to buy any other tutorials from anywhere else.
Here's all you need to know to clear this:
Skills measured
- Describe core data concepts (25-30%)
- Identify considerations for relational data on Azure (20-25%)
- Describe considerations for working with non-relational data on Azure (15-20%)
- Describe an analytics workload on Azure (25-30%)
The exam is pretty basic, so you need to be clear about all fundamentals of each term.
Have a look at the study guide for detailed topic list and some sample questions:
- Download the DP-900 study guide to help you prepare for the exam
- View free sample questions to help prepare for this exam
My Notes-
- Core Data workloads
- type of data
- data processing solutions
- batch vs stream
- Data
- Data source
- Data Mining
- Data wrangling
- Data-Related Azure services
- Azure Storage accounts
- Azure Blob storage
- Azure tables
- Azure files
- Azure Storage Explorer
- Azure Data lake Store - Gen2
- data repository for big data
- blob storage
- designed for vasts amount of data
- Azure Data Box
- import export TB os data
- mail in the HDD
- Azure Cache for REDIS
- MS Office 365 SharePoint
- Azure DataBricks
- MS Power BI
- HDInsights
- Azure Storage accounts
- Relational Data
- IaaS
- SQL Server in a VM
- PaaS
- Azure SQL MI
- Azure SQL Database
- SaaS
- Azure SQL Database vs SQL Server on Azure VMs vs MI
- Normalization
- IaaS
- NonRelational Data
- Cosmos
- Data analytics
- Azure data factory
- Azure Synapse Analytics
Azure Data concepts - relationships

- Data Engineering -Common Tools
-
Azure Synapse Studio
- azure portal
- integrated to manage
- azure synapse
- data ingestion (azure data factory)
- management of azure synapse assets (sql pools/ spark pool)
-
Azure CLI
-
Azure Databricks
-
HDinsights
-
-
Core Data workloads

-
types of data

- structured
- tabular - rows and columns - relational database
- azure Postgres, Azure MySQL, Azure SQL, Azure synapse Analytics
- semi-structured
-
some form of relationships
-
jsons, xmls

-
ORC
-
-
azure table storage (key-value) & azure cosmos db - others [MongoDB & Apache Cassandra]
-
- unstructured
- unrelated
- audios, videos
- not optimized for storage
- azure blob storage, azure files, azure data lake, MS SharePoint, Azure Disks (in VMs)
- structured
-
data processing solutions
- transactional processing | OLTP
- ACID semantics:
- Atomicity – each transaction is treated as a single unit, which succeeds completely or fails completely.
- Consistency – transactions can only take the data in the database from one valid state to another.
- Isolation – concurrent transactions cannot interfere with one another, and must result in a consistent database state.
- Durability – when a transaction has been committed, it will remain committed.
- ACID semantics:
- analytical processing | OLAP
- ingest → transform → query → visualization
- transactional processing | OLTP
-
Batch vs Streaming
-
Batch
- pros
- run during low system usage
- faster execution of repetitive tasks
- triggered conditionally
- cost effective
- cons
- result only shown on completion
- non-Real Time
- data errors can end processing of entire batch
- long running processes - taking hours to execute
- use when
- large amount of data
- need to run it on a schedule
- pros
-
Streaming
- pros
- track website usage stats live
- detect fraud
- live trade info - real time
- report on log files
- time critical
- cons
- more expensive
- must archive and secure huge amount of data
- maintaining order can be difficult
- use when
-
small size
-
real time data processing
-
producers - send data to stream
-
consumers - pull data from stream


-

- pros
-
Data source:

Database < Data Warehouse < Data Lake
Data Lakehouse

-
Data Mining
-
extraction of patterns and knowledge from large amounts of data
-
Cross Industry Standard Process for Data Mining (CRISP-DM)

- Business understanding
- what does the business need?
- data understanding
- what data do we have?
- what data do we need?
- Data Wrangling
- Data preparation
- how do we organize the data for modeling?
- Modeling
- what modeling techniques should we apply?
- Data Mining Methods
- Evaluation
- which data model best meets the business objective?
- Deployment
- how do people access the data?
- Business understanding
-
-
Data Mining Methods

-
Data Wrangling
-
transforming and mapping data from 1 raw data form into another
-
intent is to make it more valuable and appropriate for a variety of processes
-
core steps

-
Azure Cosmos DB

Azure Cosmos DB is a global-scale non-relational (NoSQL) database system that supports multiple application programming interfaces (APIs), enabling you to store and manage data as JSON documents, key-value pairs, column-families, and graphs.
In some organizations, Cosmos DB instances may be provisioned and managed by a database administrator; though often software developers manage NoSQL data storage as part of the overall application architecture. Data engineers often need to integrate Cosmos DB data sources into enterprise analytical solutions that support modeling and reporting by data analysts.
Azure Storage

Azure Storage is a core Azure service that enables you to store data in:
- Blob containers - scalable, cost-effective storage for binary files.
- File shares - network file shares such as you typically find in corporate networks.
- Tables - key-value storage for applications that need to read and write data values quickly.
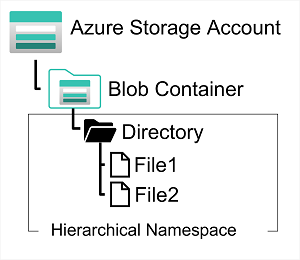
Data engineers use Azure Storage to host data lakes - blob storage with a hierarchical namespace that enables files to be organized in folders in a distributed file system.
Azure Data Factory

Azure Data Factory is an Azure service that enables you to define and schedule data pipelines to transfer and transform data. You can integrate your pipelines with other Azure services, enabling you to ingest data from cloud data stores, process the data using cloud-based compute, and persist the results in another data store.
Azure Data Factory is used by data engineers to build extract, transform, and load (ETL) solutions that populate analytical data stores with data from transactional systems across the organization.
Azure Synapse Analytics

Azure Synapse Analytics is a comprehensive, unified data analytics solution that provides a single service interface for multiple analytical capabilities, including:
- Pipelines - based on the same technology as Azure Data Factory.
- SQL - a highly scalable SQL database engine, optimized for data warehouse workloads.
- Apache Spark - an open-source distributed data processing system that supports multiple programming languages and APIs, including Java, Scala, Python, and SQL.
- Azure Synapse Data Explorer - a high-performance data analytics solution that is optimized for real-time querying of log and telemetry data using Kusto Query Language (KQL).
Data engineers can use Azure Synapse Analytics to create a unified data analytics solution that combines data ingestion pipelines, data warehouse storage, and data lake storage through a single service.
Data analysts can use SQL and Spark pools through interactive notebooks to explore and analyze data, and take advantage of integration with services such as Azure Machine Learning and Microsoft Power BI to create data models and extract insights from the data.
Azure Databricks

Azure Databricks is an Azure-integrated version of the popular Databricks platform, which combines the Apache Spark data processing platform with SQL database semantics and an integrated management interface to enable large-scale data analytics.
Data engineers can use existing Databricks and Spark skills to create analytical data stores in Azure Databricks.
Data Analysts can use the native notebook support in Azure Databricks to query and visualize data in an easy to use web-based interface.
Azure HDInsight

Azure HDInsight is an Azure service that provides Azure-hosted clusters for popular Apache open-source big data processing technologies, including:
- Apache Spark - a distributed data processing system that supports multiple programming languages and APIs, including Java, Scala, Python, and SQL.
- Apache Hadoop - a distributed system that uses MapReduce jobs to process large volumes of data efficiently across multiple cluster nodes. MapReduce jobs can be written in Java or abstracted by interfaces such as Apache Hive - a SQL-based API that runs on Hadoop.
- Apache HBase - an open-source system for large-scale NoSQL data storage and querying.
- Apache Kafka - a message broker for data stream processing.
Data engineers can use Azure HDInsight to support big data analytics workloads that depend on multiple open-source technologies.
Azure Stream Analytics

Azure Stream Analytics is a real-time stream processing engine that captures a stream of data from an input, applies a query to extract and manipulate data from the input stream, and writes the results to an output for analysis or further processing.
Data engineers can incorporate Azure Stream Analytics into data analytics architectures that capture streaming data for ingestion into an analytical data store or for real-time visualization.
Azure Data Explorer

Azure Data Explorer is a standalone service that offers the same high-performance querying of log and telemetry data as the Azure Synapse Data Explorer runtime in Azure Synapse Analytics.
Data analysts can use Azure Data Explorer to query and analyze data that includes a timestamp attribute, such as is typically found in log files and Internet-of-things (IoT) telemetry data.
Microsoft Purview

Microsoft Purview provides a solution for enterprise-wide data governance and discoverability. You can use Microsoft Purview to create a map of your data and track data lineage across multiple data sources and systems, enabling you to find trustworthy data for analysis and reporting.
Data engineers can use Microsoft Purview to enforce data governance across the enterprise and ensure the integrity of data used to support analytical workloads.
Microsoft Power BI

Microsoft Power BI is a platform for analytical data modeling and reporting that data analysts can use to create and share interactive data visualizations. Power BI reports can be created by using the Power BI Desktop application, and then published and delivered through web-based reports and apps in the Power BI service, as well as in the Power BI mobile app.
-











- Data-Related Azure services
-
Azure Storage accounts
umbrella service for various storage
- Azure Blob storage
- data stores for objects
- distributed storage - span across multiple machines
- Azure tables
- key value noSQL data store
- simpler projects
- Azure files
- file shares NFS or SMB
- Azure Blob storage
-
Azure Storage Explorer
- installed app | can be used to browse the data within storage accounts
-
Azure Data lake Store - Gen2
- data repository for big data
- blob storage
- designed for vasts amount of data
-
Azure Data Box
- import export TB os data
- mail in the HDD
-
Azure Cache for REDIS
-
MS Office 365 SharePoint
- shared file-system
- fine grain role based access control
-
Azure DataBricks
- 3rd party
- azure + Apache
- very fast | ETL jobs and ML, streaming
-
MS Power BI
- create dashboard and reports
-
HDInsights
- fully managed hadoop system
- ETL and ELT
-
Azure Data Factory
-

-
Relational Data

- IaaS
- SQL Server in a VM
- Benefits
- MS manages all hardware concerns
- disk, memory and processor are maintained with 99.99% availability
- auto hardware HA and DR
- easy to scale capacity up or down
- Licensing
- pay as you go | per minute usage
- bring your own license
- Migration
- Azure Lift and Shift
- Storage
- place data, log and tempdb files on separate drives
- please tempdb on local ssd drive (deallocates resource when VM is stopped)
- High Availability
-
database level
- database backups
- local drive
- or azure blob storage
- automated backups
- automatic service | creates & stores backups | no DBA
- SQL Server Always on Availability groups
- replicate data | set of user DBs → one or more secondary sql server instances on different VMs
- all these nodes are clustered at OS level
- example - bare minimum setup
- 1 secondary node | same region | HA
- 1 secondary node | different region | DR
- Secondary node | can be a Non-Azure VM (onPrem)
- requires VPN connectivity | between Azure network (SQL azure VM) <-> onPrem SQL server VM network
- database backups
-
VM level
- HA & DR
-
storage level
→ create copies of data and store them on azure blob storage
- Locally redundant storage | 3 copies | same location & region
- Geo redundant storage | 3 copies in same region | 3 copies in separate region
-
- Deploy
-
portal
- powershell
-
- Benefits
- Azure Disks
- VMs
- SQL Server in a VM
- PaaS
-
Azure SQL MI
- Benefits
- Hardware maintained by MS
- MS will monitor and perform routine maintenance tasks
- security patches, database backups and DR are automated
- DBA can focus only on performance
- near 100% compatibility with SQL Enterprise edition
- SQL logins and AD auth are both supported
- Benefits
-
Azure SQL Database
- best suited for new databases
- compatible with core SQL server functionality
- Benefits
- fully managed maintenance, backups, security and resource allocation
- 99.995% uptime
- point-in-time restores are allowed
- geo-redundant replication copies and sync db around the globe
- advanced threat monitoring
- Cons
- does not support full set of capabilities
- less compatible migration (onPrem to Azure)
- Configuration types
- Single DB
- full database in cloud
- simply log in and create tables
- resources pre-allocated
- only single db queries
- Elastic Pool
- pre-allocated resources shared by multiple databases
- supports fluctuations in database activity
- Serverless
- single databases are placed in an elastic pool
- this elastic pool will be shared by databases of many different azure subscribers
- MS sets resources allocation levels
- resources are transferred between databases
- additional wait times
- lower costs
- Single DB
-
Azure SQL Edge
- highly specialized solution
- help store and analyze high volumes real time data
- used for IoT apps
- ML capabilities
- deployed to individual devices through small footprint containers
- pricing per device
- protects against latency and bandwidth disruptions
-
Azure Databases for MySql, PSQL, MariaDB
- open source databases
- high availability built-in
- pay as you go
- data is encrypted
- automatic backups
- security protection
-
CosmosDB
-
HD Insights
-
- SaaS
- Azure Data Analytics
- Big Data as a Service
- write u-Sql to return data from your Azure Data lake
- PowerBI
- Office 365
- Azure Data Analytics
- IaaS


Row-store vs Column-Store

- Normalization
-
1NF
-
each entity requires its own table
-
move any column which is not directly related to another table
This:

Transformed into:

-
-
2NF
-
every columns should only store a single piece of info
-
allows you to choose/filter on a specific column in query
-
benefits
- less data redundancy
This:

transformed into:

-
-
3NF
-
every row needs to be uniquely identifiable (Primary Key)
-
Combine 2- more columns to make a row unique
This:

Transformed into:

-
-






- NonRelational Data
-
Azure Storage
unstructured..

-
Azure Blob storage
-
features
-
store massive amount of data as blobs

-
blob - binary large objects
-
apps can read write → using azure blob storage API
-
-
Access options
- Azure storage REST API
- Azure powershell
- Azure CLI
- Azure storage client library
-
Use cases
- serve images/documents directly to browser
- storing files for distributed access
- streaming video and audio
- writing to log file
- storing data for backups, DR and archiving
- storing data for analysis
-
Blob storage resource
-
Storage account
- unique name space
-
container
- used to organize
- read and write access can be set at this level
-
blob
-
Virtual folders

-
-
Types of Blobs
- Block blob
- set of blocks
- 50k blocks
- 1 block = max 4k MB
- 1 block blob = max 190TB
- best for large object that don’t change often
- Page blob
- collection of fixed size page
- 1 page = fixed 512bytes
- 1 page blob = max 8TB
- optimized for random Read and Write
- best for virtual disks → Azure VMs
- Append Blobs
- Block blob → optimized to support append
- only possible to add blocks at the end
- 1 block = max 4mb
- 1 append blob = max 195GB
- best for → logging data
- Block blob
-
Blob storage access Tiers
- Tiers
- Hot tier
- data that’s accessed frequently
- high performance & high cost
- Cool tier
- less frequent use data
- less cost and performance
- Archive tier
- data that’s rarely used
- can take hours to access data
- lowest cost
- Hot tier
- Blob lifecycle management policies
- automatically delete blobs if required
- move blobs from hot to cool tiers based on usage
- Tiers
-
-
Azure Data Lake Storage Gen2

- service → used for hierarchical data storage for analytical data lakes
- used by Big data solutions
- Can use blob storage + cost controlled tiers + hierarchical file system
- Systems can mount a distributed filesystem disk hosted in Azure Data Lake storage Gen2
- Hadoop in Azure HDinsights
- Azure Databricks
- Azure Synapse Analytics
- Create
- Enable Hierarchical namespace option in Azure storage account
- during Azure storage account creation
- upgrade the account (downgrade is not possible)
- Enable Hierarchical namespace option in Azure storage account
-
Azure File storage
- Traditional file sharing
- onPrem servers
- NAS storage devices
- files placed on those file shares
- users are granted access to files
- Azure File Storage Pros
- Cloud based file-shares that are available globally
- onPrem HW not required
- no maintenance
- HA
- scalable
- Stats
- 1 storage account = 100TB shared data
- each file share can have quota to limit the size
- Max size of single file = 1TB
- 2k concurrent connections → per shared file
- uploading options
- Azure portal
- AzCopy Utility
- Azure File Sync
- Performance tiers
- Standard | use HDD
- Premium | uses SSD
- Storage access
- SMB
- NFS
- Azure files REST API
- Use cases
- shared app settings
- diagnostics tools
- Traditional file sharing
-
Azure Table storage

-
uses tables to store data
-
key-value store
-
simpler to scale. It consumes the same time to insert data in an empty table or a table with billions of entries. An Azure storage account can consist of up to 500 TB of data.
-
storage account → contain any number of tables
-
no fixed schema

- store semi-structured data
- no. of columns differ per row
- data structure can change in future
-
user cases
- user data for web apps
- address books
- device info
-
no concept of → FK, relationships, SPs
-
Denormalized
- very fast performance
-
Primary key = PartitionKey + RowKey
- Many partitions
- Partition benefits
- scalability
- performance
- Partition benefits
- rows go from 1 to N in each partition
- Row key ordering benefits
- Point query | locate single row
- range query | fetch block of rows
- Many partitions
-
Timestamp = date of modification
-
-
Plan
- Benefits of storage accounts?
- why would you use it?
- what use cases do they have?
-
-
CosmosDB

-
fully managed NoSQL database
-
multi model | multiple APIs available
-
indexes are automatically maintained
-
global scale
- multi region writes
- data copies in different zones
-
highly scalable
- can store massive volumes of data
- elastic scaling
- automatically allocates space in containers
- each partition can grow → 10GB
-
encryption at rest and in motion
-
Cosmos DB APIs

-
Core SQL API
- SQL code
- JSON document → result
-
API for MongoDB
-
MQL
-
BSON document → result
- binary JSON

-
-
Table API
-
similar to Azure Table storage
-
higher scalability
-
Data → key-value pairs
-
Use case | using Azure table storage
-
Results
- call the service end point

-
-
Cassandra API
-
compatible with Apache cassandra
-
Data → column-family structure
- column-family are tables
- every row can have different columns
-
Use case | if you want to use native Apache Cassandra features, tools
-
CQL

-
-
Gremlin API
-
data → graph structure
-
focus on relationships

-
use case | dynamic data, complex relationships or complex data model
-
-
-
various engines | Core mode:
-
tables
-
documents
-
key-value
-
graph

-
-
-












- Data analytics
-
examining, transforming and arranging data
-
common tools
- sql, BI and spreadsheets
-
Data analytics workflow

-
Azure Modern Data Warehouse

-
-


- Data ingestion and processing
-
Azure Data Factory
-
Azure Synapse Analytics
-
both have same engine

-
Azure data factory (similar to SSIS)
- managed ETL/ELT pipeline builder
- implement complex data integration service
- web interface
- cloud based integration service
- data driven workflows
- data orchestration
- publishes transformed data to other services
- you can call DataBricks from Azure data factory pipeline
-
Azure Synapse Analytics
-
data warehouse
-
Azure synapse pipeline
- linked services
- connection string
- connection to data source (external resources)
- example
- Azure storage linked service | connection string
- Azure blob dataset | blob container and folder with data
- datasets
- data structures within data stores
- inputs and outputs
- activities
- processing steps in a pipeline
- types
- data movement
- data transformation
- control activities
- example
- copy activity for copying data over
- reads data from source
- triggers
- kick off pipeline execution
- types
- schedule
- tumbling window
- event based
- pipelines
- child pipelines
- logical grouping of activities (performing units of work)
- manage activities as a set
- different pipelines can work in parallel or sequentially
- linked services
-
Data ingestion
- petabyte → 1k TB scale ingestion
-
unified analytics platform

-
run ETL/ELT
-
complete model

-
Massively Parallel Processing (MPP)
-
to process TBs of data.. parallel processing is a must
-
architecture
- Control node distributes the load → to Compute nodes

-
-
-




- Analytical Data Store
- data store
- serve processed data in structured format
- queried using analytical tools
- Types
-
Data warehouse
-
large scale
-
relational database
-
store + query engine
-
data is de-normalized
- stored as dimensions and facts
- best used when you have your data coming from a SQL source

-
-
Data Lake
- files stored in distributed file system
- supports → structured, semi and unstructured data
- high performance data access
- example
- storing IoT readings in azure
-

-
implement a Large scale analytical store
- Azure services
- Azure Synapse Analytics
- Azure synapse studio
- manage all Synapse services
- Azure synapse studio
- Azure Databricks
- Data analytics solution
- built on Apache Spark
- languages → R, Python & Scala
- Azure HDinsight
- open source
- use open source libraries
- Azure Synapse Analytics

- Azure services

-
Real Time Analytics in Azure
-
Azure Stream analytics

- Azure stream analytics job and Azure subscription
- configure input and output
- define the query → job will use to process the data
-
Spark Structured streaming
- Azure synapse analytics
- Azure databricks
- azure HDInsight
-
Azure Data Explorer
- Kusto Query Language (KQL)
-
-
Services used to ingest data for Stream processing
- Sources
- Azure Event Hubs
- Azure IoT Hub
- Azure Data lake storage Gen2
- Apache Kafka
- Output/sinks for streaming processing
- Azure Event hubs
- Azure Data lake storage Gen2
- Azure SQL database
- Power BI
- Sources
-
Data Lake Analytics
- U-SQL is the language that is used to define a job that contains queries to transform data and extract insights into data lake analytics.
- Data Lake Analytics provides a framework and collection of tools that is used to analyze data stored in Microsoft Azure Data Lake Store
-
Data Analytics Techniques:
-
they are subset of one another
-
Techniques
- Descriptive
- Diagnostic
- Predictive
- Prescriptive
- Cognitive

-
Data Analytics Techniques
-
Descriptive | WHAT happened?
-
Diagnostic | WHY did it happen?
-
Predictive | WHAT will happen?
-
Prescriptive | HOW can we make it happen?
-
Cognitive | WHAT if this happens?
-
-


- That's it. This is what you need to know.
All the Best for the exam.


Comments
Post a Comment